The people opposing the library's plan for a new downtown library are calling themselves "Save A2 Parks", on the grounds that the plan would use, in part, this:
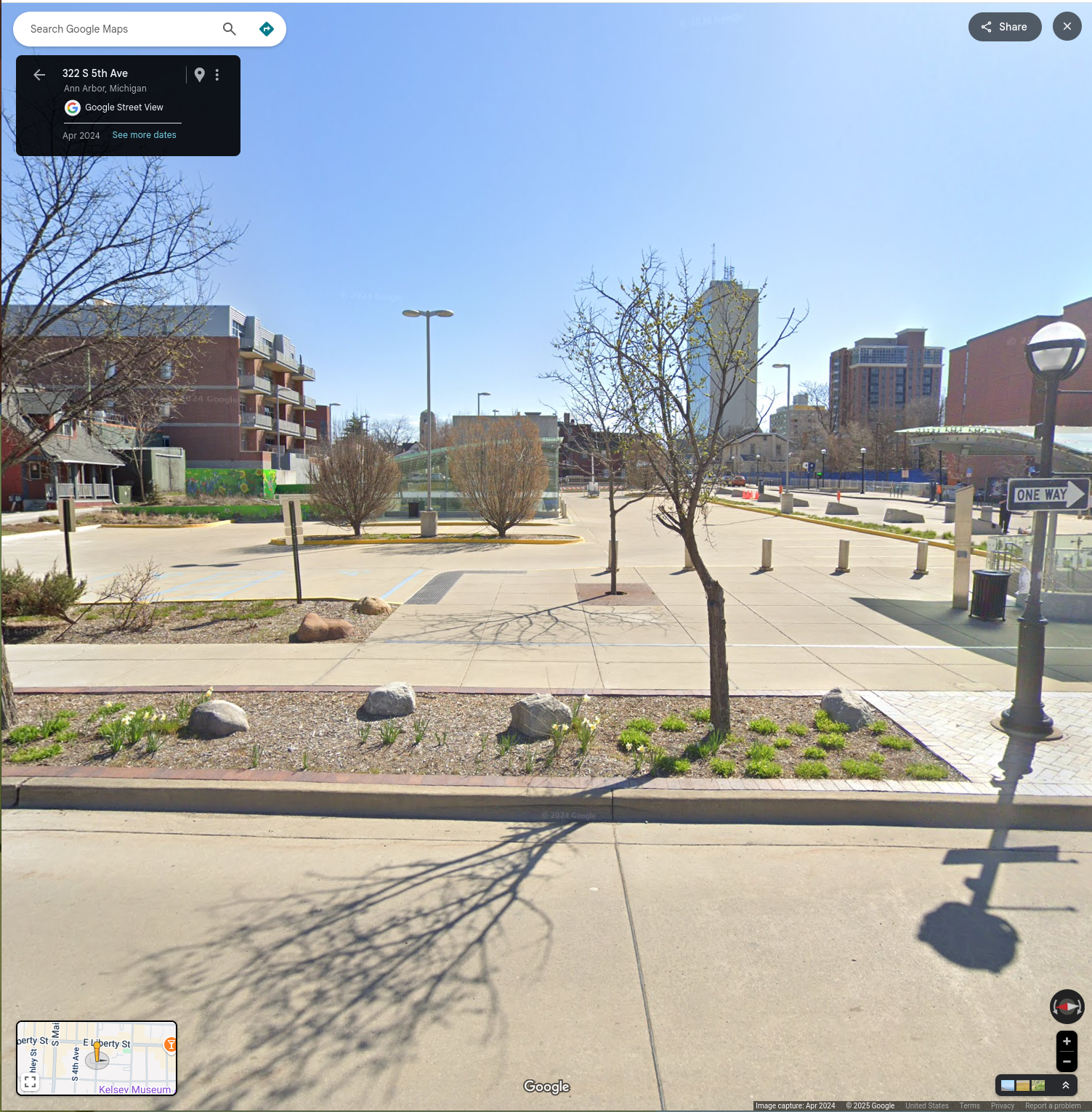
No, your eyes are not decieving you. It's less a park, more a parking lot. (In fact, it's the top of an underground parking structure.) Their objection rests on the idea that it could be turned into a park. The history of this whole idea is long and tortured, but suffice it to say that the idea turns out to be about as feasible as you'd expect.
"Save A2 Parks" is remarkably reminiscent of an earlier group, "Protect A2 Parks", which was formed to block a plan to build a train station in Fuller Park. But wait, what was the actual exact location of the proposed train station?
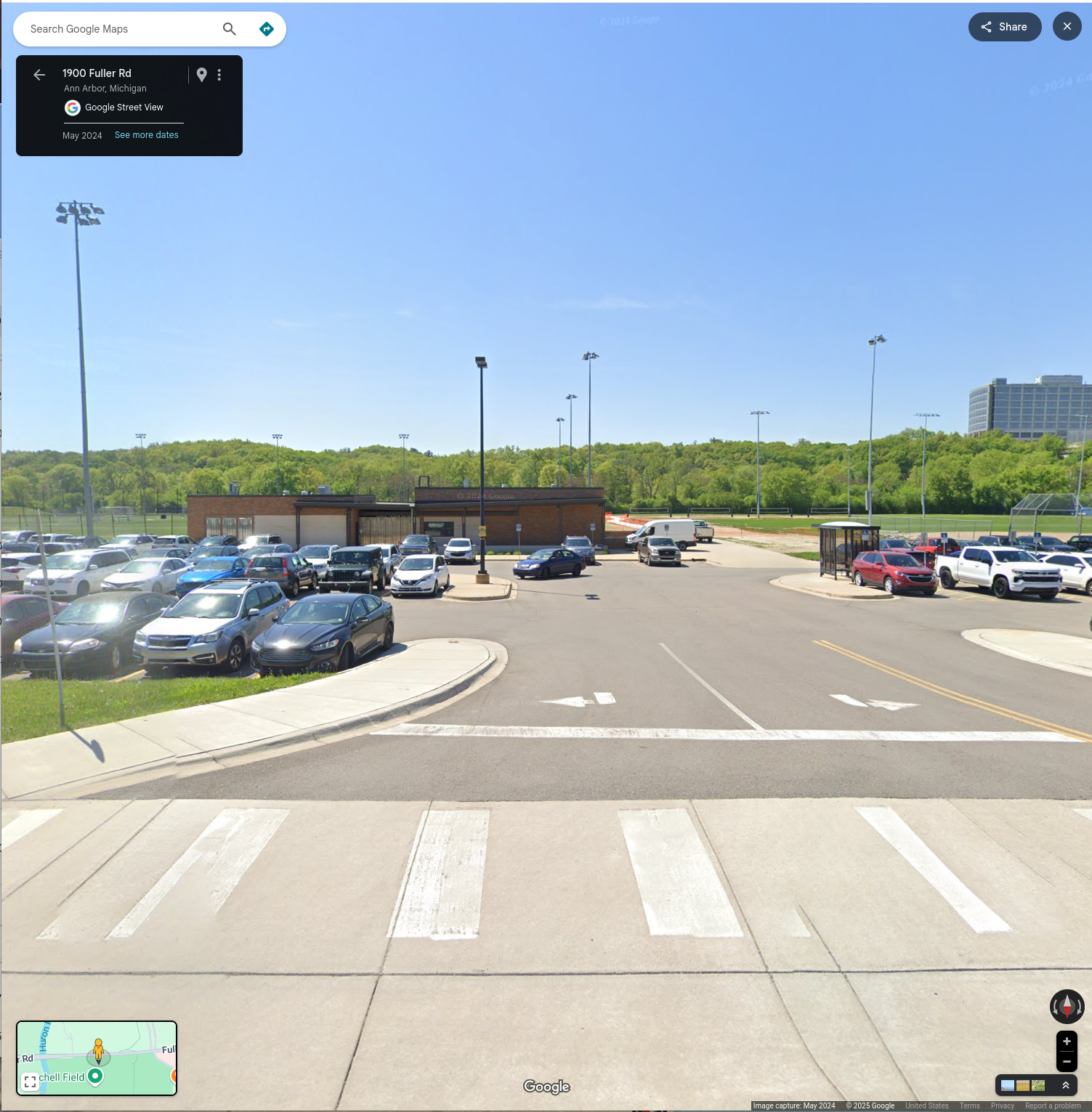
Yep, another parking lot! And, once again, there was some claim that this parking lot could also be park, a complicated story involving a long-term lease to UM. You will not be surprised to learn that it is still, today, a parking lot.
Some of the same people are involved. They seem to have trouble distinguishing parks from parking.
More history, if you really want it:


